The Research division works to create open-source tools and software to assist historians in researching and presenting their own findings, as well as engaging with the scholarship of others. During our four-week rotation in this division, we learned about and experimented with PressForward, primarily through working with DH Now, and RRCNHM’s newest tool, Tropy.
First, we took a closer look at Digital Humanities Now, a website that acts as a distribution platform for digital humanities based scholarly work in various formats from blog posts to white papers, as well as conference and job announcements from the field. Coming into the Research Division, we were somewhat familiar with DH Now as we had been using it all semester to stay current on what was happening in the DH field. However, I was less clear on the actual underpinning of how DH Now worked. I knew that multiple feeds were brought into the WordPress site and from there, DH Now staff and GRAs curated those feeds, choosing what to publish on the website.
In fact, as we learned, DH Now is powered by PressForward, a WordPress plugin created by the Research Division at RRCHNM that allows one to easily aggregate and share content from the web. DH Now is only one of multiple websites that use the plugin to aggregate and share scholarly web content.
We then were tasked with using our new knowledge of PressForward and DH Now to serve as the Editors-in-Chief for a week, reading through nominated content, choosing what would be the best material to publish, and even selecting the Editor’s Choice piece. Through this hands-on experience, we were able to get a sense of how DH Now worked from the editors’ perspective, instead of from more of a consumer’s view.
Finally, we worked with Laura Crossley, one of the Editors-in-Chief of DH Now, to install and use the PressForward plugin on our own scholarly websites. Laura uses PressForward, much like DH Now, to aggregate DH content on her own blog and share her own comments about what is happening in the field. After considering several options, I decided to use PressForward on my personal website in a less extensive, but still quite useful way. Up until this semester, my personal website has contained blog post updates about my coursework and progress through the Graduate Certificate in Digital Public Humanities. Now I have also begun publishing these posts on the RRCHNM Fellows Blog. It is likely that in the near future, I will also publish blog posts or other scholarly web content in places other than my personal website. Therefore, I am excited to be using PressForward on my own website to bring together a collection of my work in one location. This will allow me to do a better job of keeping track of my own work, while also offering a place for others to examine the various ways I have engaged in the scholarly conversation.
Secondly, we spent time experimenting with and learning about Tropy, the newest research tool built by RRCHNM. Tropy had been released just prior to the beginning of our rotation in the Research Division, so we were some of the first people outside of the Tropy team to really get to see what Tropy can do. Like many of the projects carried out in the Research Division that try to solve a current problem troubling historians, Tropy gives a solution for what to do with the thousands of pictures that scholars take during trips to the archives. We were challenged to experiment with Tropy by reading the documentation, downloading the software, importing some of our own research materials and finally, creating a metadata template for that material.
As a historian of Early America, dealing mostly with handwritten documents, I found that Tropy is extremely useful. It allows you to easily import images and group them into documents, which is helpful if you have a multi-page document and a separate image for each page. Next, there is special split screen view (document on top, space to type underneath), which allows you to transcribe the documents right in Tropy. Before Tropy, I had been keeping my transcriptions (as Word documents) and image files (in a photo editor) separately, but Tropy allows you to save them together, which is really helpful. Tropy also has a search feature, so that you can find every occurrence of a certain person or place’s name in the documents you have transcribed, instead of manually reading through text files to find what you are looking for.
A big part of Tropy, and the second part of our task, was to deal with the metadata associated with our documents. Tropy comes preloaded with a basic template and a few more specific ones (ex. for correspondence or photos). The templates differ in the metadata that they ask you to add for each item. For example, the generic one asks for information like title, date, item type, source, holding collection, etc. while the correspondence template asks for the title, author, recipient, date, location, archive it is from, etc. The metadata properties have to come from an established vocabulary (ex. Dublin Core) but users can import other vocabularies available through Linked Open Vocabularies (LOV). Users can also download templates that others have made or upload templates they had made.
For my experiment in creating a Tropy template, I used material from a previous research project about a rape case in Fairfax County, Virginia during the Civil War. While my research had been supplemented by government and prison records held at the Library of Virginia and newspaper records at the Fairfax County Library, the core of my research centered around the case file for the trial, which is held at the Fairfax Circuit Court Historic Records Center, in Fairfax, VA.
Originally, I thought that I might make a template that could be used for all material at the Historic Records Center, as that would be helpful to a larger group of people if uploaded and shared. My thinking was that I could add the Historical Records Center as the Default Value for the Source property, and that way, users would not have to type that in for every item. But as I tried to create a generic template that would encapsulate all the types of sources held at the Historic Records Center (wills, deed books, birth, death and marriage records, road petitions, as well as court documents), my template ended up being no different than the “Tropy Generic” template that comes with the software.
So I decided to take a different approach and focus on making a template just for the Term Papers at the Historic Records Center. This class of documents provides the legal judgments for each case, and includes any court papers filed during the term of court. As I knew from my research, item properties like “creator” were less important than determining things like the plaintiff, defendant, and case type (murder, debt, trespass, assault, etc.). After a long search through the properties and vocabularies that came with Tropy, I found that I could use the Dublin Core property “Subject” to stand in for the case type, but that there were no good properties already in Tropy to describe the Plaintiff and Defendant. Therefore, I used Linked Open Vocabularies to find a vocabulary through the Library of Congress (MARC Code List for Relators) that included these two properties. Next, I downloaded the vocabulary and imported it into Tropy, where I could add the two properties to my template. Here is a sample of my template:
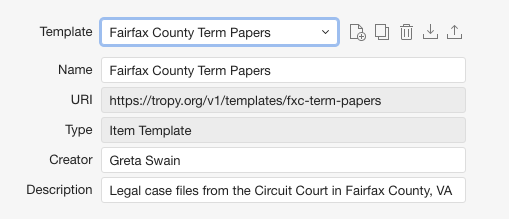
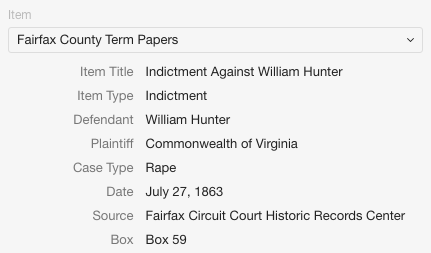
Overall, I enjoyed my time in the Research Division. It was really interesting to see how the team in this division had identified two problems common to the historical profession–namely, how to get more publicity/recognition for scholarly grey material and how to organize images of documents from archival research–and how they worked to create usable solutions to these problems. I also appreciated the chance to see how these tools could be incorporated into my own scholarly work and blog.