We have spent the last few weeks working to build a python script that would allow us to download and prep all of the THATCamp blog posts for topic modeling in MALLET (for those catching up, we detailed this process in a series of previous posts). As our last post detailed, we encountered a few more complications than expected due to foreign languages in the corpus of the text. After some discussion, we worked through these issues and were able to add stoplists to the script for German, French, and Spanish. Although this didn’t solve all of our issues and some terms do still show up (we didn’t realize there was Dutch too), it led to some interesting discussion about the methodology behind topic modeling. Finally we were able to rerun the python script with the new stopwords and then feed this new data into MALLET.
MALLET, or MAchine Learning for Language Toolkit, is an open source java package that can be used for natural language processing. We used the Programming Historian’s tutorial on MALLET. Topic modeling is an important digital tool that analyzes a corpus of text and seeks to extract ‘topics’ or sets of words that are statistically relevant to each other. The result is a particular number of word sets also known as “topics.” In our case we asked MALLET to return twenty topics based on our set of THATCamp blog posts. The topics returned by MALLET were:
- xa digital art history research university scholarship graduate field center publishing open today institute cultural knowledge professor online world
- university games pm humanities http digital september knowledge kansas saturday game conference state registration play information representation workshop boise
- thatcamp session sessions day participants free technology page unconference university nwe conference discussion information google propose hope event proposals
- people make time questions things idea access process ideas world work great making lot build add kind interesting nthe
- digital humanities data tools text projects research scholars omeka texts tool analysis scholarly archive reading online based book scholarship
- digital humanities session dh library libraries support projects open discussion librarians amp talk work journal sessions propose faculty list
- history public digital historical collections museum media project projects mobile online maps museums collection historians users sites site applications
- games zotero thinking place game code end cultural chnm hack year documentation humanists version number pretty application visualization set
- session open area data workshop tool knowledge teach interested bay prime bootcamp gis workshops reality night thatcampva virginia lab
- work interested students ways teaching post working talk writing blog love issues don conversation create collaborative thinking start discuss
- project web content information tools community resources archives experience research create learn creating learning share development materials specific provide
- xb xa del se humanidades digitales xad al madrid www mi este aires buenos digital personas taller cuba parte
- caption online id align width open attachment accessibility women read university american building accessible gender media november floor race
- data http org session www open twitter texas good wikipedia nhttp status wiki start commons drupal metadata people crowd
- xa workshop session omeka publishing http gt propose org workshops friday docs open hands amp doc studies topic discuss
- students digital learning technology education media college faculty humanities research game pedagogy student courses classroom assignments skills arts social
- xa oral digital humanities video event local application community offer interviews planning center education software jewish weekend college histories
- een het voor op te zijn deze met workshop kunnen om digitale bronnen data onderzoek historici nl wat worden
- social media technology studies arts performance museums xcf play participants cultural performing reading st email object platforms interaction technologies
- xa thatcamp org http thatcamps details read movement published planned access nthatcamp browse software follow break series google join
As you can see we have an impressive list of terms. Before we organize them in a meaningful way, we will briefly point out a common problem that scholars may confront when working with MALLET. As you may notice, we realized that we have quite a few errors such as ‘xa’ that appear in the results. While we don’t have a great answer for why this is, we think it has to do with complex encoding issues related to moving content from a WordPress post that is stored in a MySQL database using Python. Each of these uses a different coding system and the error appears to be related to non-breaking spaces. A little bit of Googling revealed that the non-breaking space character used by WordPress is ‘ ’ which is different that the ASCII encoding of a non-breaking space ‘/xa0’. When Python reads WordPress’s non-breaking space character ‘ ’, it understands the space but encodes it as the UTF-8 version ‘/xa0’. As second year fellow Spencer Roberts explained the issue is that meaning is lost in translation. He used this analogy: Python reads and understands the French word for “dog” then translates it and returns the English word.
In this case, what shows up in our results is not ‘/xa0’ but rather ‘xa’ because we had stripped out all of the non-alphanumeric characters prior to running the data through MALLET. We think the errors such as ‘xa’ and ‘xb’ are because of these encoding issues. Anyone interested in clarifying or continuing this discussion with us can do so in the comments.
Returning to our MALLET results, our next challenge was to present and analyze the large amount of data. We drew from both Cameron Blevins and Robert K. Nelson in our approach and decided to group the topics by theme so that trends could be more easily identified. We determined that there were about seven broad themes in the corpus of THATCamp blog posts from 2008 to present:
- Accessibility
- Building
- Community
- International
- Pedagogy
- Public Digital Humanities
- THATCamp Structure
Utilizing these larger categories, we were able to create several charts that demonstrate the changes over time with the THATCamps. The charts are available below; you’ll note that we have graphed them using percentages. The percentages that appear represent the number of times that topic occurred within the posts at that camp.
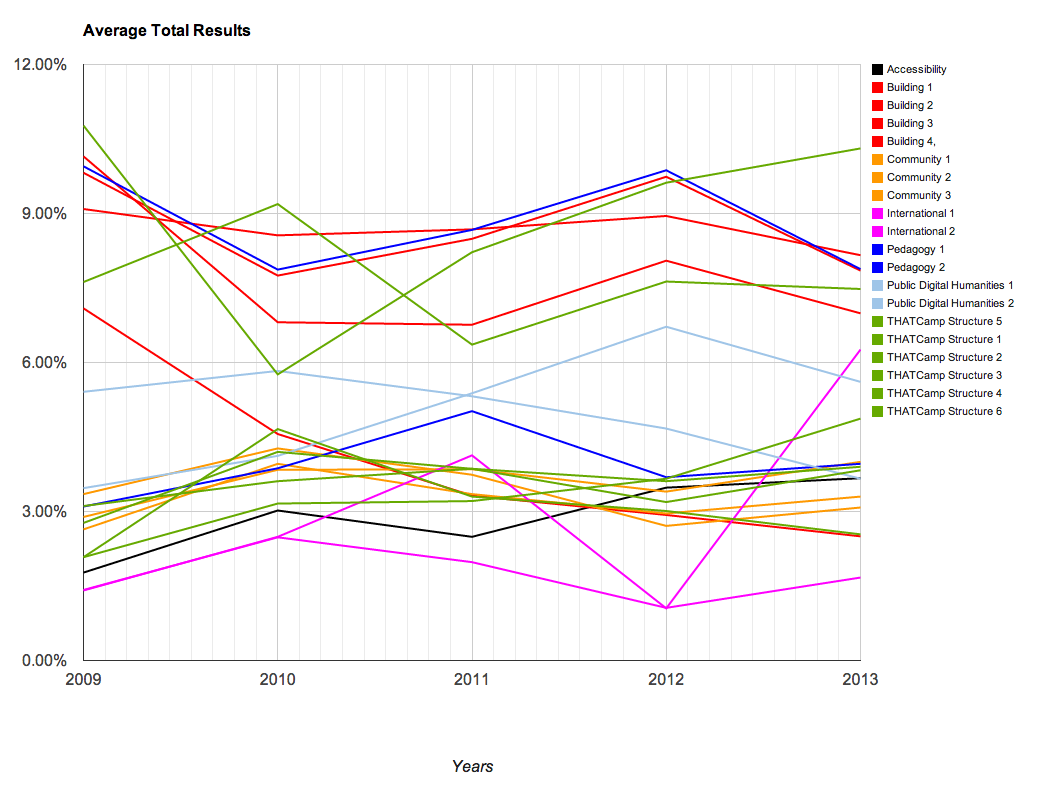
Topics Overall
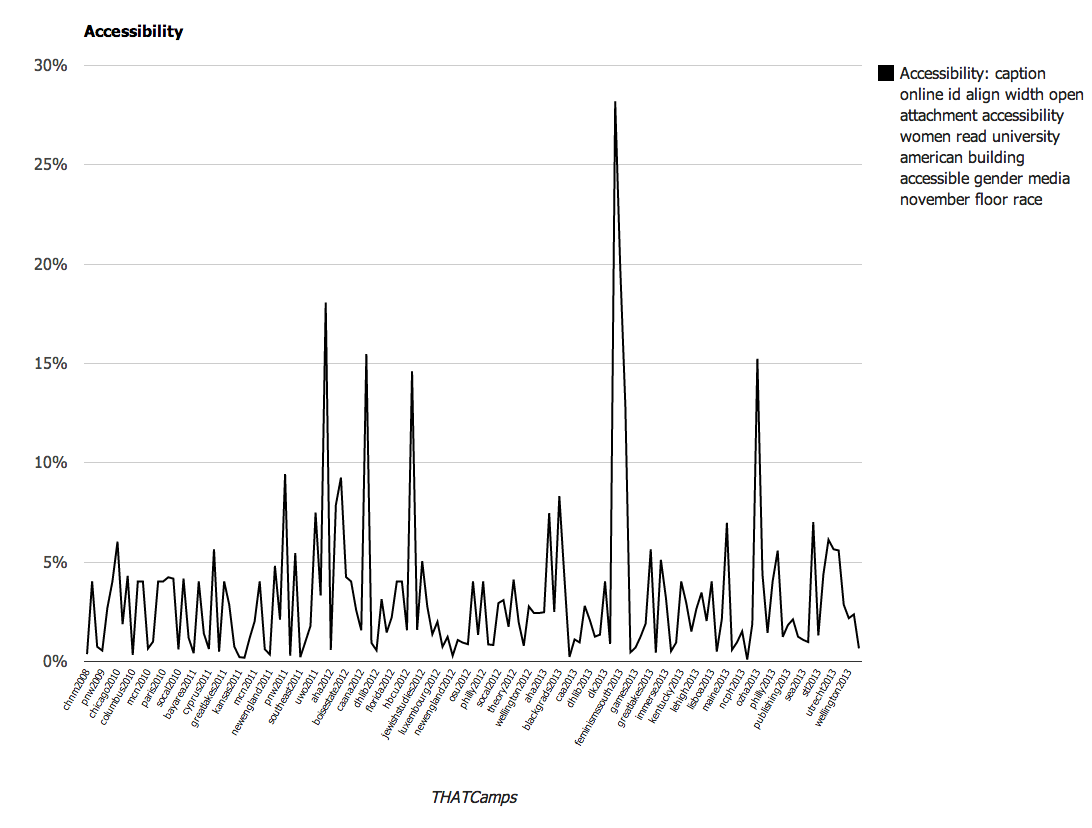 Topics relating to Accessibility |
 Topics relating to Community |
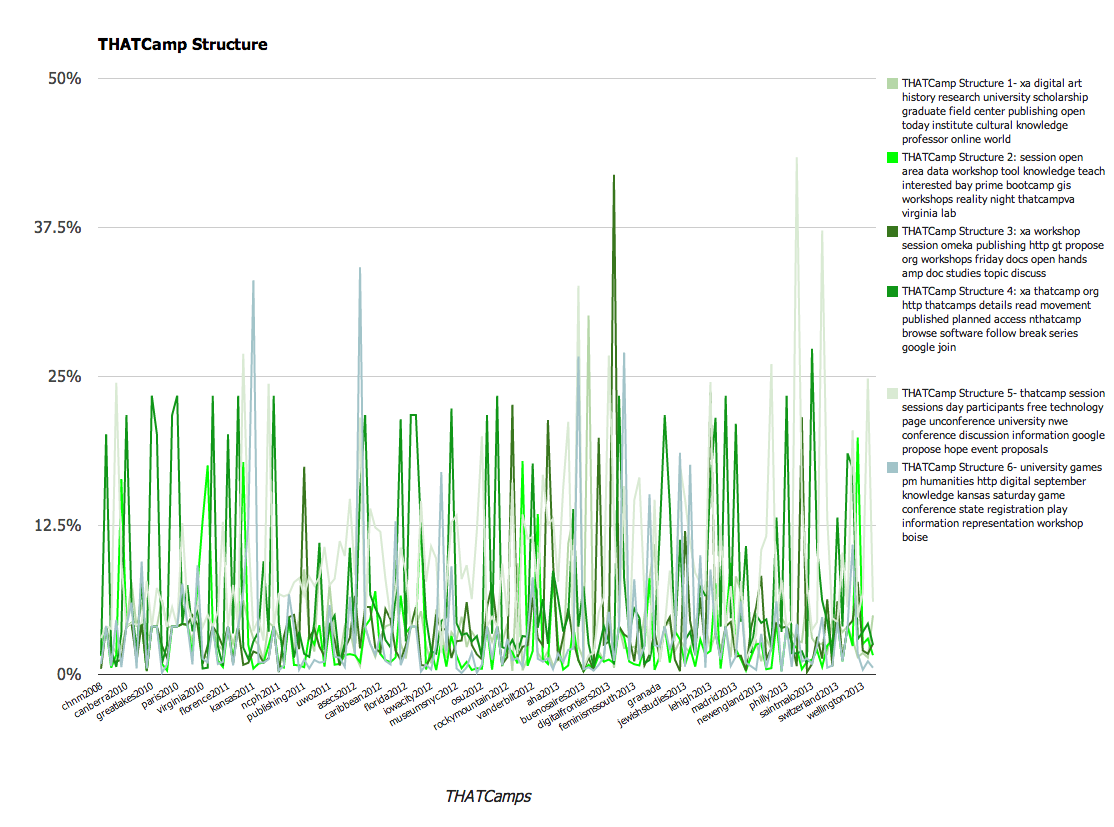 Topics relating to THATCamp Structure |
 Topics relating to Pedagogy |
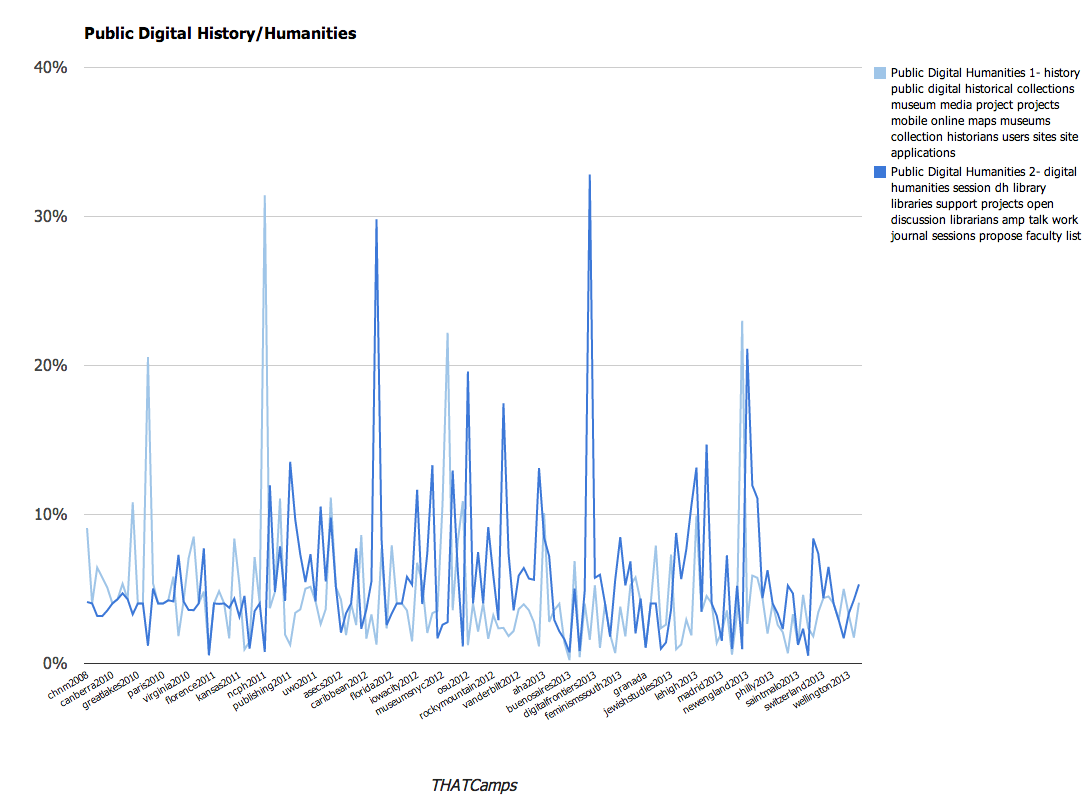 Topics relating to Public Digital Humanities |
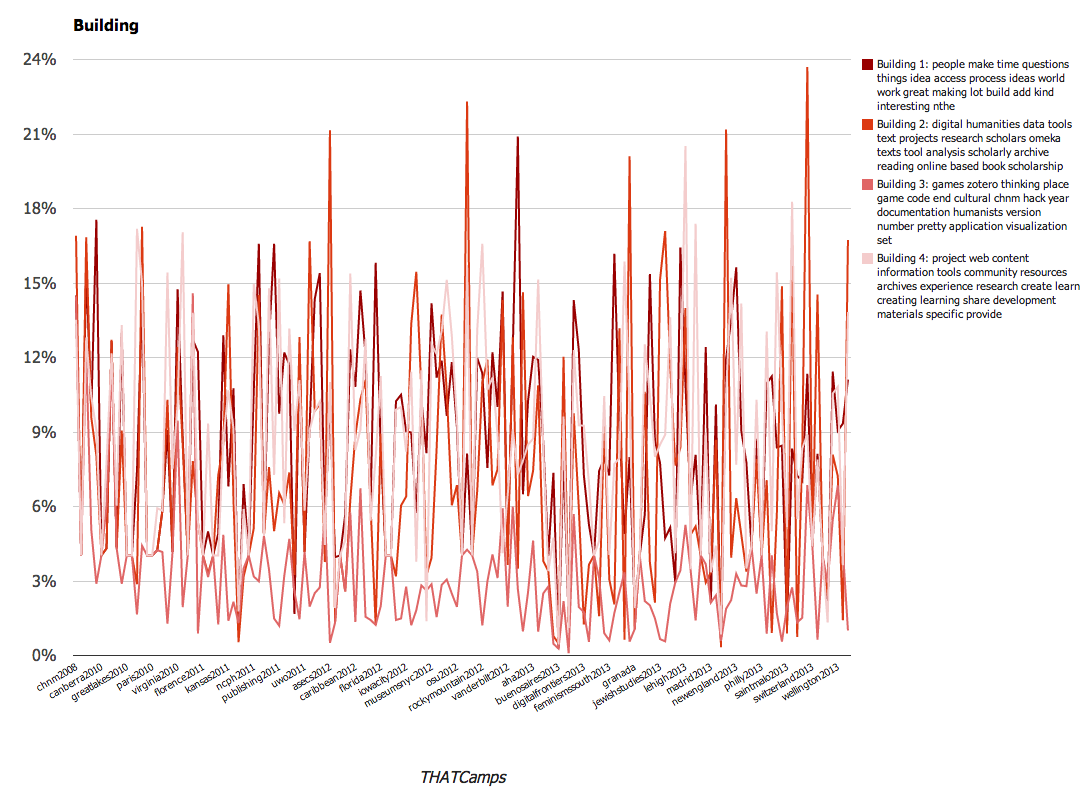 Topics relating to Building |
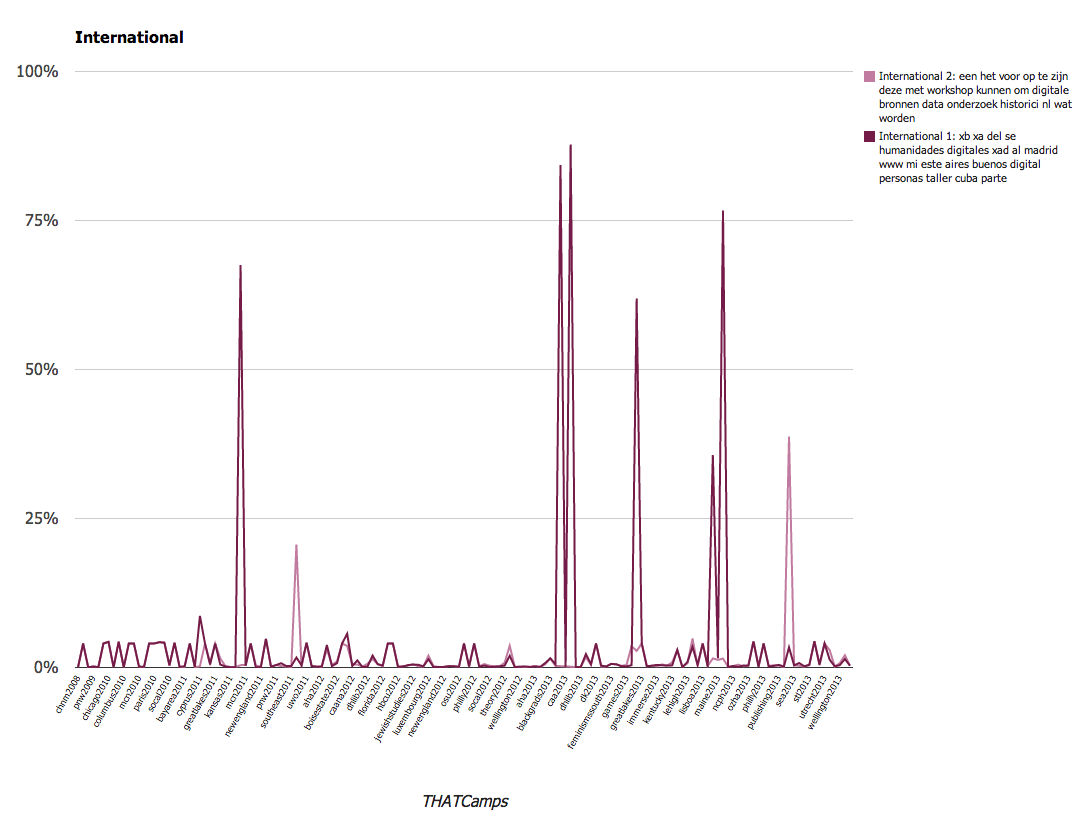 International Digital Humanities |
We found these results to be particularly interesting. A larger overall conclusion is that THATCamp content emphasizes the various applications of digital technology to scholarship, from public uses to tool building or teaching. Since THATCamp was founded, it has become a more varied community. However close examination of the topic models this exercise produced reveals that a number of the same terms appear frequently across all of the topic models (“digital”, for instance, appears in 8 of the 20 topics). This references the way in which ideas are circulated throughout camps and unifies the community. It also reflects the subjects that are the focus of the community.
If you’re interested in the data, you can view the various files here:
- Averages for each year and the overall chart (Google Spreadsheet)
- Data for each individual camp and charts by grouping (Google Spreadsheet)
- Data from MALLET
- Raw data